


Linear Regression is a supervised machine learning algorithm where the predicted output is continuous and has a constant slope. The linear regression model has a linear relationship between the dependent and independent variable.
Let x be the independent variable and y be the dependent variable. We will define a linear relationship between these two variables as follows:
y = a_0 + a_1*x
where a_1 is the slope of the line and a_0 is the y-intercept. This equation will be used for predicting the value of Y. Before moving on to the algorithm, let’s have a look at two important concepts to understand linear regression.
Loss function: It is the function used to find the best value of a_1 and a_0. We will use mean squared error by following steps:
- Find the difference between the actual and predicted value of y for given x.
- Square the difference
- Find the mean of squares for every value of x.
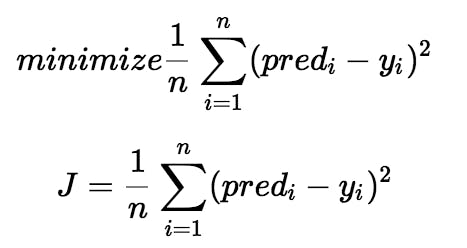
- Gradient descent algorithm: It is an optimization algorithm used to find the minimum of function. In linear regression, it used to minimize the cost function, by updating the value of a_1 and a_0.
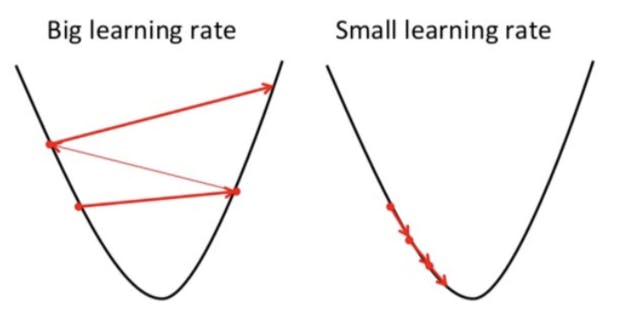
Imagine a ‘U’ shaped valley. Suppose our aim is to reach the bottommost position. We start from the topmost position. There is a catch, you can only take a discrete number of steps to reach the bottom. If you decide to take one step at a time you would eventually reach the bottom of the valley but this would take a longer time. If you choose to take longer steps each time, you would reach sooner but, there is a chance that you could overshoot the bottom of the valley and not exactly at the bottom.
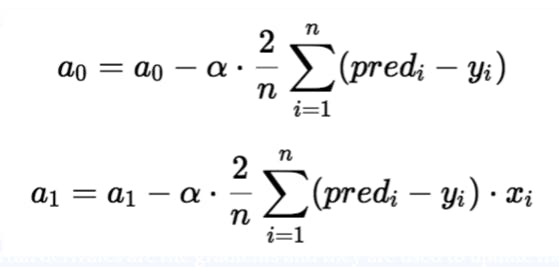
In the gradient descent algorithm, the number of steps you take is the learning rate. This decides on how fast the algorithm converges to the minima. To update a_1 and a_0, we take gradients from the loss function. To find these gradients, we take partial derivatives with respect to a_1 and a_0.
The partial derivates are the gradients and they are used to update the values of a_1 and a_0. Alpha is the learning rate which is a hyperparameter. A smaller learning rate could get you closer to the minima but takes more time to reach the minima, a larger learning rate converges sooner but there is a chance that you could overshoot the minima.
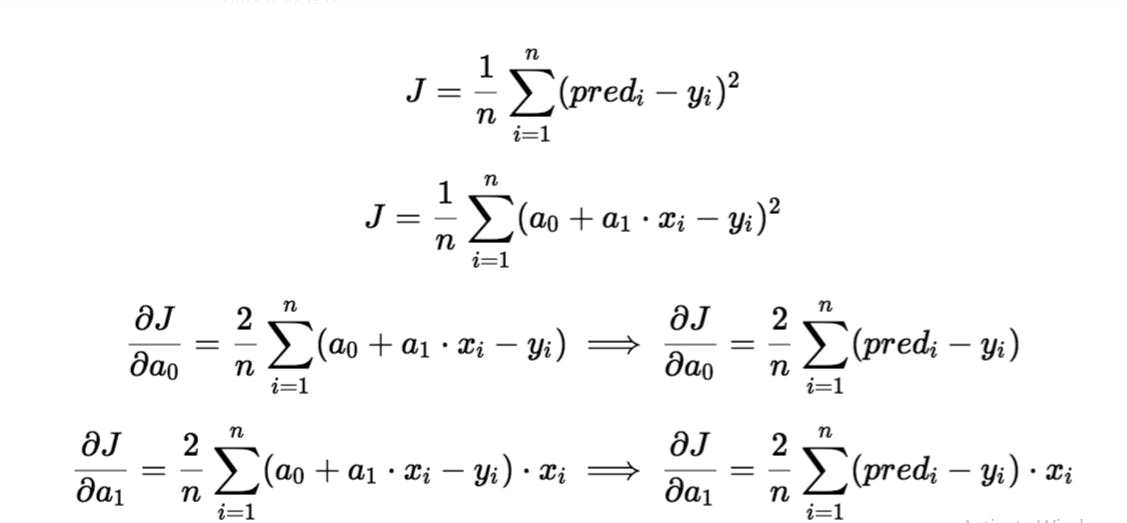
Linear Regression selection criteria:
- classification and regression capabilities
- data quality (outliers can affect)
- computational complexity
Implementation: I have used this dataset , which consists of marks scored by students and no. of hour student studied. Our aim is to predict the marks scored by the student.
- Code using the above discussion of loss function and gradient descent.
#import required libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#reading data from given link
url = "http://bit.ly/w-data"
df = pd.read_csv(url)
X = df.iloc[:, 0]
Y = df.iloc[:, 1]
plt.scatter(X, Y)
plt.show()
# Building the model
m = 0
c = 0
L = 0.0001 # The learning Rate
epochs = 1000 # The number of iterations to perform gradient descent
n = float(len(X)) # Number of elements in X
# Performing Gradient Descent
for i in range(epochs):
Y_pred = m*X + c # The current predicted value of Y
D_m = (-2/n) * sum(X * (Y - Y_pred)) # Derivative wrt m
D_c = (-2/n) * sum(Y - Y_pred) # Derivative wrt c
m = m - L * D_m # Update m
c = c - L * D_c # Update c
print (m, c)
9.896964110671043 1.6314708810783134
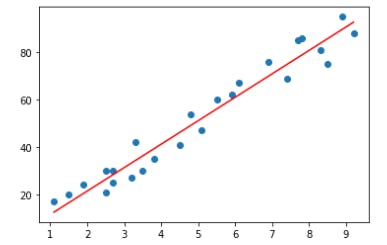
Y_pred = m*X + c
plt.scatter(X, Y)
plt.plot([min(X), max(X)], [min(Y_pred), max(Y_pred)], color='red') # predicted
plt.show()
- Code using scikit learn library can be found here .
Linear Regression is used for evaluating and analyzing trends and sales estimate, assessment of risk in the financial sector and insurance domain etc.
Conclusion: Linear Regression is a very useful and simple algorithm of machine learning.
Hope you find this article helpful. Keep learning!